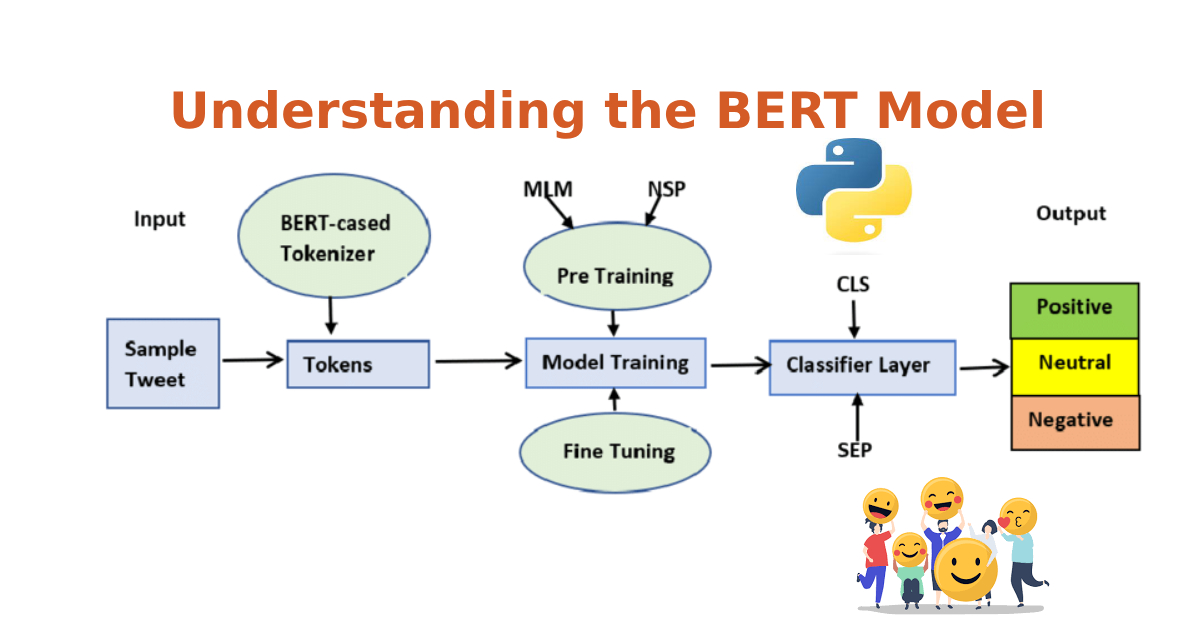
BERT, which stands for Bidirectional Encoder Representations from Transformers, has revolutionized the world of natural language processing (NLP). Developed by researchers at Google in 2018, BERT provides a deep bidirectional representation of text, allowing it to achieve state-of-the-art results on a multitude of NLP tasks.
In this article, we’ll dive deep into the BERT model, understand its architecture and functioning, and explore some Python coding examples to implement and utilize BERT.
1. BERT’s Underlying Architecture: Transformers
The foundation of BERT is the Transformer architecture. A transformer uses attention mechanisms to capture contextual information from the entire input sequence in its representation, unlike models such as LSTM or GRU, which read sequentially.
Attention Mechanism
The attention mechanism allows the model to focus on different parts of the input text when producing an output. In essence, it calculates a weight for each input word for a given output word.
2. What Makes BERT Special: Bidirectionality
Traditional language models, like LSTM and GRU, are either unidirectional or combine two unidirectional representations. BERT, on the other hand, is inherently bidirectional. This bidirectionality allows BERT to understand the context of each word in a sentence more holistically.
For instance, in the sentence “He went to the bank to withdraw money,” the word “bank” can mean a financial institution. But in “He sat by the bank of the river,” “bank” refers to the side of a river. BERT can differentiate between these meanings based on context.
3. Pre-training and Fine-tuning
BERT’s success largely stems from its two-step process:
- Pre-training: BERT is first trained on a large corpus (like the entire Wikipedia) using masked language modeling. Some words in a sentence are masked, and the model tries to predict them based on surrounding words.
- Fine-tuning: For specific tasks, BERT is then fine-tuned on task-specific data. This process allows BERT to be adapted to a wide variety of tasks with relatively small datasets.
4. BERT Variants
BERT comes in various sizes:
- BERT-Base
- BERT-Large
- And others, like DistilBERT (a distilled, smaller version of BERT)
Each variant has a trade-off between computational intensity and accuracy.
Python Coding Examples with BERT
Now, let’s see BERT in action with some Python coding examples. For this, we’ll use the transformers library, which provides easy-to-use implementations of BERT and other transformer models.
Installing the library:
!pip install transformersTokenizing Input:
Before feeding text to BERT, it needs to be tokenized:
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
tokens = tokenizer.tokenize("Hello, BERT!")
print(tokens)
Output:
['hello', ',', 'bert', '!']Extracting Embeddings:
Here’s how you can get BERT embeddings for a piece of text:
from transformers import BertModel
# Tokenizing input
text = "Hello, BERT!"
tokens = tokenizer.tokenize(text)
token_ids = tokenizer.convert_tokens_to_ids(tokens)
token_ids = tokenizer.encode(text, add_special_tokens=True) # Adds [CLS] and [SEP] tokens
model = BertModel.from_pretrained('bert-base-uncased')
with torch.no_grad():
outputs = model(torch.tensor([token_ids]))
embeddings = outputs.last_hidden_state
print(embeddings[0])
Fine-tuning for Classification:
For tasks like sentiment analysis, you can fine-tune BERT:
from transformers import BertForSequenceClassification
# Assume train_data is a list of tuples with (text, label)
train_data = [("This is great!", 1), ("I didn't like it.", 0)]
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# Convert data to appropriate format
input_ids = [tokenizer.encode(text, add_special_tokens=True) for text, label in train_data]
labels = torch.tensor([label for text, label in train_data])
# Train model (a simple example, in reality, you'd use a DataLoader and optimize over batches)
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
for epoch in range(3):
model.train()
for i, (input_id, label) in enumerate(zip(input_ids, labels)):
outputs = model(torch.tensor([input_id]), labels=torch.tensor([label]))
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Save the model
model.save_pretrained('./sentiment_model')
Conclusion:
BERT has undoubtedly become one of the cornerstones of modern NLP, providing a versatile approach to understanding the intricacies of human language. Whether you’re just starting or are a seasoned practitioner, the power and adaptability of BERT, combined with libraries like transformers, enable a wide range of NLP applications.


