
Businesses keenly need such things as the efficient extraction, transformation, and loading of data, or ETL, in order to gain valuable insights from any data-driven […]
Tag: Spark

Enhancing Efficiency and Scalability using Serverless Architectures in Data Engineering
Introduction In the rapidly evolving world of data engineering, serverless architectures have emerged as a game-changing technology. These architectures, where the management of servers is […]

Catalyzing Insights: Unraveling NYC’s 311 Service Requests with Apache Spark and Elasticsearch
Introduction: Apache Spark offers unparalleled capabilities for processing large datasets, making it indispensable for big data tasks. In this guide, we’ll delve into the 311 […]

Getting Started with PySpark
Python is an immensely popular programming language, and when it comes to processing large datasets, PySpark stands out as a powerful tool. Whether you’re a […]
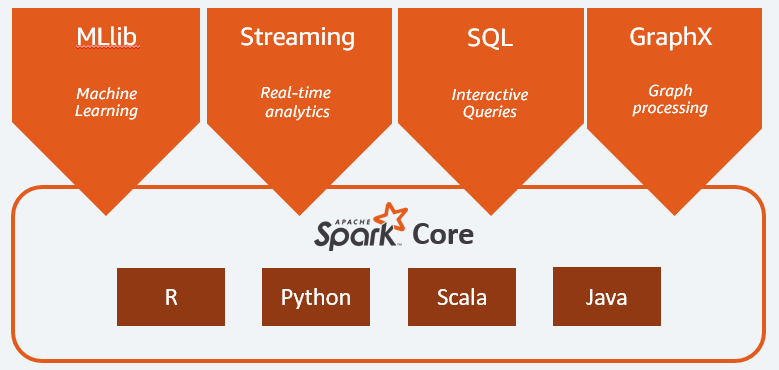
Introduction to Apache Spark
Introduction Apache Spark is a robust framework for processing data, enabling swift execution of tasks on extensive datasets. It excels in distributing data processing across […]