Introduction
Apache Spark is a robust framework for processing data, enabling swift execution of tasks on extensive datasets. It excels in distributing data processing across multiple computers, both independently and in conjunction with other distributed computing tools. These crucial attributes make it indispensable in the realms of big data and machine learning, where immense computational power is essential for handling vast data repositories. Additionally, Spark simplifies programming for developers through its user-friendly API, relieving them of the complexities associated with distributed computing and processing large-scale data.
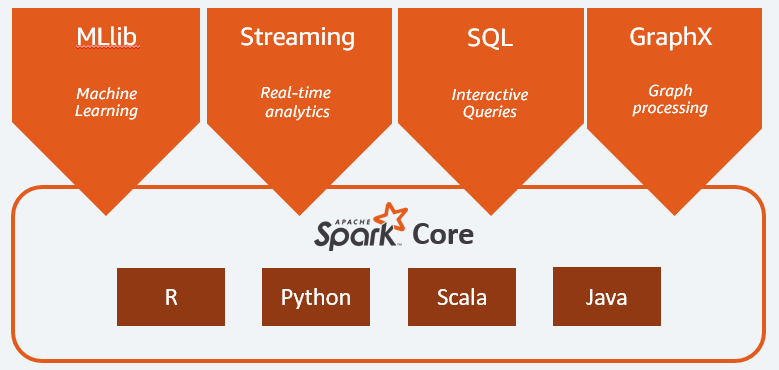
Since its inception at the esteemed AMPLab at U.C. Berkeley in 2009, Apache Spark has evolved into a prominent distributed processing framework for big data. Its versatility is evident in its ability to be deployed in various manners, offering native support for popular programming languages like Java, Scala, Python, and R. Furthermore, Spark encompasses a wide range of functionalities, including SQL, streaming data processing, machine learning, and graph processing. Its extensive adoption spans across diverse sectors, including banking, telecommunications, gaming, government agencies, and major tech titans like Apple, IBM, Meta, and Microsoft.
Spark RDD
At the core of Apache Spark lies the fundamental notion of the Resilient Distributed Dataset (RDD), which serves as a programming abstraction to represent an unchanging collection of objects that can be divided across a computing cluster. These RDDs enable operations to be split and executed in parallel batches across the cluster, facilitating rapid and scalable parallel processing. Apache Spark transforms the user’s commands for data processing into a Directed Acyclic Graph (DAG), which acts as the scheduling layer determining the sequencing and allocation of tasks across nodes.
RDDs can be effortlessly generated from various sources such as plain text files, SQL databases, NoSQL repositories like Cassandra and MongoDB, Amazon S3 buckets, and many more. The Spark Core API heavily relies on the RDD concept, offering not only traditional map and reduce functionalities but also integrated support for data set joining, filtering, sampling, and aggregation.
Spark runs in a distributed fashion by combining a driver core process that splits a Spark application into tasks and distributes them among many executor processes that do the work. These executors can be scaled up and down as required for the application’s needs.
Spark SQL
Spark SQL has become more and more important to the Apache Spark project. It is the interface most commonly used by today’s developers when creating applications. Spark SQL is focused on the processing of structured data, using a dataframe approach borrowed from R and Python (in Pandas). But as the name suggests, Spark SQL also provides a SQL2003-compliant interface for querying data, bringing the power of Apache Spark to analysts as well as developers.
Alongside standard SQL support, Spark SQL provides a standard interface for reading from and writing to other datastores including JSON, HDFS, Apache Hive, JDBC, Apache ORC, and Apache Parquet, all of which are supported out of the box. Other popular data stores—Apache Cassandra, MongoDB, Apache HBase, and many others—can be used by pulling in separate connectors from the Spark Packages ecosystem. Spark SQL allows user-defined functions (UDFs) to be transparently used in SQL queries.Nominations are open for the 2024 Best Places to Work in IT
Selecting some columns from a dataframe is as simple as this line of code:
citiesDF.select("name", "pop")Using the SQL interface, we register the dataframe as a temporary table, after which we can issue SQL queries against it:
citiesDF.createOrReplaceTempView("cities")
spark.sql("SELECT name, pop FROM cities")Behind the scenes, Apache Spark uses a query optimizer called Catalyst that examines data and queries in order to produce an efficient query plan for data locality and computation that will perform the required calculations across the cluster. Since Apache Spark 2.x, the Spark SQL interface of dataframes and datasets (essentially a typed dataframe that can be checked at compile time for correctness and take advantage of further memory and compute optimizations at run time) has been the recommended approach for development. The RDD interface is still available, but recommended only if your needs cannot be addressed within the Spark SQL paradigm (such as when you must work at a lower level to wring every last drop of performance out of the system).
Spark MLlib and MLflow
Apache Spark also bundles libraries for applying machine learning and graph analysis techniques to data at scale. MLlib includes a framework for creating machine learning pipelines, allowing for easy implementation of feature extraction, selections, and transformations on any structured dataset. MLlib comes with distributed implementations of clustering and classification algorithms such as k-means clustering and random forests that can be swapped in and out of custom pipelines with ease. Models can be trained by data scientists in Apache Spark using R or Python, saved using MLlib, and then imported into a Java-based or Scala-based pipeline for production use.
An open source platform for managing the machine learning life cycle, MLflow is not technically part of the Apache Spark project, but it is likewise a product of Databricks and others in the Apache Spark community. The community has been working on integrating MLflow with Apache Spark to provide MLOps features like experiment tracking, model registries, packaging, and UDFs that can be easily imported for inference at Apache Spark scale and with traditional SQL statements.
Structured Streaming
Structured Streaming is a high-level API that allows developers to create infinite streaming dataframes and datasets. As of Spark 3.0, Structured Streaming is the recommended way of handling streaming data within Apache Spark, superseding the earlier Spark Streaming approach. Spark Streaming (now marked as a legacy component) was full of difficult pain points for developers, especially when dealing with event-time aggregations and late delivery of messages.
All queries on structured streams go through the Catalyst query optimizer, and they can even be run in an interactive manner, allowing users to perform SQL queries against live streaming data. Support for late messages is provided by watermarking messages and three supported types of windowing techniques: tumbling windows, sliding windows, and variable-length time windows with sessions.
In Spark 3.1 and later, you can treat streams as tables, and tables as streams. The ability to combine multiple streams with a wide range of SQL-like stream-to-stream joins creates powerful possibilities for ingestion and transformation. Here’s a simple example of creating a table from a streaming source:
val df = spark.readStream
.format("rate")
.option("rowsPerSecond", 20)
.load()
df.writeStream
.option("checkpointLocation", "checkpointPath")
.toTable("streamingTable")
spark.read.table("myTable").show()Structured Streaming, by default, uses a micro-batching scheme of handling streaming data. But in Spark 2.3, the Apache Spark team added a low-latency Continuous Processing mode to Structured Streaming, allowing it to handle responses with impressive latencies as low as 1ms and making it much more competitive with rivals such as Apache Flink and Apache Beam. Continuous Processing restricts you to map-like and selection operations, and while it supports SQL queries against streams, it does not currently support SQL aggregations. In addition, although Spark 2.3 arrived in 2018, as of Spark 3.3.2 in March 2023, Continuous Processing is still marked as experimental.
Structured Streaming is the future of streaming applications with the Apache Spark platform, so if you’re building a new streaming application, you should use Structured Streaming. The legacy Spark Streaming APIs will continue to be supported, but the project recommends porting over to Structured Streaming, as the new method makes writing and maintaining streaming code a lot more bearable.
Delta Lake
Like MLflow, Delta Lake is technically a separate project from Apache Spark. Over the past couple of years, however, Delta Lake has become an integral part of the Spark ecosystem, forming the core of what Databricks calls the Lakehouse Architecture. Delta Lake augments cloud-based data lakes with ACID transactions, unified querying semantics for batch and stream processing, and schema enforcement, effectively eliminating the need for a separate data warehouse for BI users. Full audit history and scalability to handle exabytes of data are also part of the package.
And using the Delta Lake format (built on top of Parquet files) within Apache Spark is as simple as using the delta format:
df = spark.readStream.format("rate").load()
stream = df
.writeStream
.format("delta")
.option("checkpointLocation", "checkpointPath")
.start("deltaTable")Pandas API on Spark
The industry standard for data manipulation and analysis in Python is the Pandas library. With Apache Spark 3.2, a new API was provided that allows a large proportion of the Pandas API to be used transparently with Spark. Now data scientists can simply replace their imports with import pyspark.pandas as pd and be somewhat confident that their code will continue to work, and also take advantage of Apache Spark’s multi-node execution. At the moment, around 80% of the Pandas API is covered, with a target of 90% coverage being aimed for in upcoming releases.
Running Apache Spark
At a fundamental level, an Apache Spark application consists of two main components: a driver, which converts the user’s code into multiple tasks that can be distributed across worker nodes, and executors, which run on those worker nodes and execute the tasks assigned to them. Some form of cluster manager is necessary to mediate between the two.
Out of the box, Apache Spark can run in a stand-alone cluster mode that simply requires the Apache Spark framework and a Java Virtual Machine on each node in your cluster. However, it’s more likely you’ll want to take advantage of a more robust resource management or cluster management system to take care of allocating workers on demand for you.
In the enterprise, this historically meant running on Hadoop YARN (YARN is how the Cloudera and Hortonworks distributions run Spark jobs), but as Hadoop has become less entrenched, more and more companies have turned toward deploying Apache Spark on Kubernetes. This has been reflected in the Apache Spark 3.x releases, which improve the integration with Kubernetes including the ability to define pod templates for drivers and executors and use custom schedulers such as Volcano.
If you seek a managed solution, then Apache Spark offerings can be found on all of the big three clouds: Amazon EMR, Azure HDInsight, and Google Cloud Dataproc.
Databricks Lakehouse Platform
Databricks, the company that employs the creators of Apache Spark, has taken a different approach than many other companies founded on the open source products of the Big Data era. For many years, Databricks has offered a comprehensive managed cloud service that offers Apache Spark clusters, streaming support, integrated web-based notebook development, and proprietary optimized I/O performance over a standard Apache Spark distribution. This mixture of managed and professional services has turned Databricks into a behemoth in the Big Data arena, with a valuation estimated at $38 billion in 2021. The Databricks Lakehouse Platform is now available on all three major cloud providers and is becoming the de facto way that most people interact with Apache Spark.
Apache Spark tutorials
Ready to dive in and learn Apache Spark? We recommend starting with the Databricks learning portal, which will provide a good introduction to the framework, although it will be slightly biased towards the Databricks Platform. For diving deeper, we’d suggest the Spark Workshop, which is a thorough tour of Apache Spark’s features through a Scala lens. Some excellent books are available too. Spark: The Definitive Guide is a wonderful introduction written by two maintainers of Apache Spark. And High Performance Spark is an essential guide to processing data with Apache Spark at massive scales in a performant way. Happy learning!