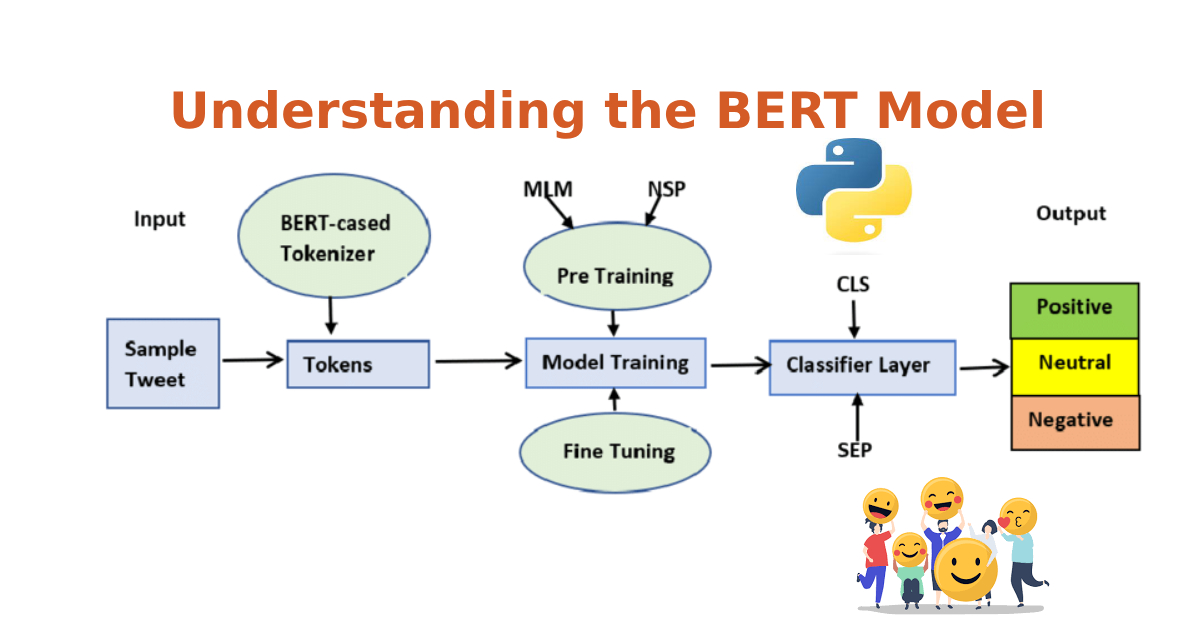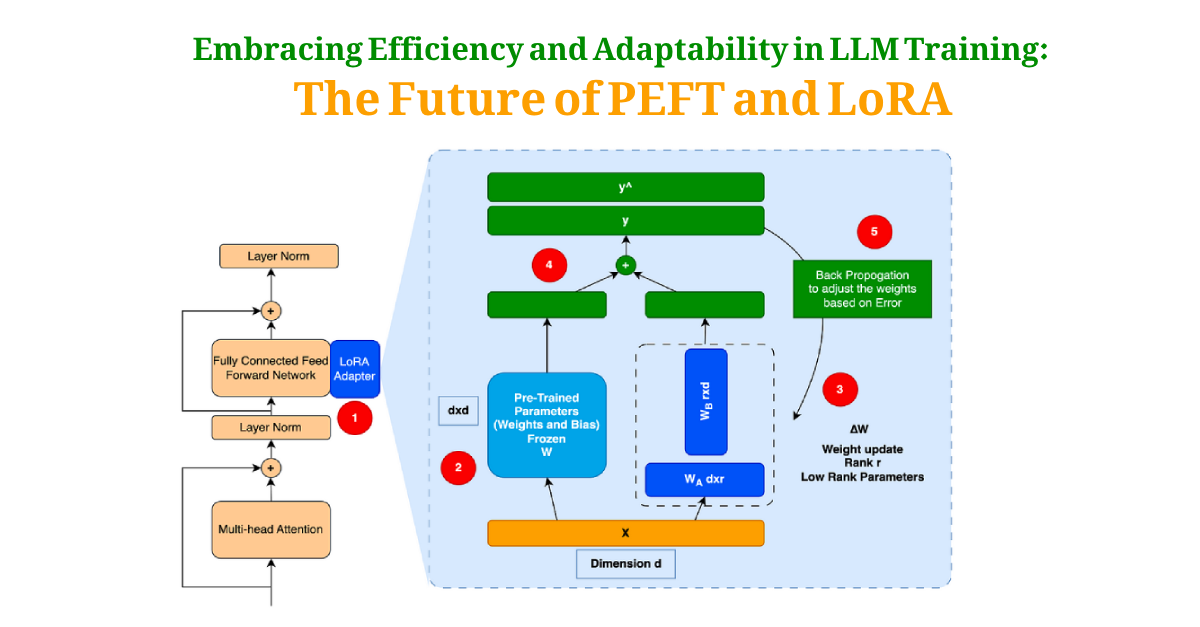
Introduction:
Large Language Models (LLMs) like GPT (Generative Pre-trained Transformer) have revolutionized the field of natural language processing (NLP). These models have an extraordinary ability to understand, generate, and translate human language. Training such models is a complex and resource-intensive process. In this article, we delve into the various methods employed to train LLMs, highlighting their unique approaches and the outcomes they aim to achieve.
Supervised Learning:
The most common method for training LLMs is supervised learning. This approach requires a dataset with input-output pairs, where the model learns to predict the output from the input. For LLMs, this typically involves large corpora of text with corresponding tasks, such as translation pairs or text with summarization. The model’s performance is continuously evaluated, and adjustments are made to minimize the difference between the predicted and actual outputs.
Unsupervised Learning:
Unsupervised learning involves training a model without explicit feedback. For LLMs, this could mean learning to predict the next word in a sentence without being given a specific task. The model identifies patterns, structures, and relationships within the data on its own. This method is particularly useful for understanding language in a broader context and is often used to pre-train models before fine-tuning them with supervised learning.
Semi-supervised Learning:
This method combines both supervised and unsupervised learning. An LLM might be pre-trained on a vast corpus of text in an unsupervised manner and then fine-tuned on a smaller, task-specific dataset. Semi-supervised learning leverages the vast amount of unlabeled data available while still benefiting from the precision that labeled data provides.
Reinforcement Learning:
Reinforcement learning (RL) trains models through a system of rewards and penalties. An LLM trained with RL might be tasked with generating sentences that are then evaluated by either humans or automated systems. Positive outcomes lead to rewards, encouraging the model to repeat those actions, while negative outcomes result in penalties, discouraging those actions.
Transfer Learning:
Transfer learning involves taking a model that has been trained on one task and adapting it to a new task. For LLMs, this means taking a model that has been pre-trained on a large dataset and then fine-tuning it on a specific dataset related to a particular task or domain. This method is highly efficient as it allows the model to transfer the knowledge it has already acquired to a new context.
Few-shot Learning:
Few-shot learning is a training approach where the model learns to perform a task with a very small amount of training data. LLMs like GPT-3 have demonstrated remarkable few-shot learning capabilities, where they can understand and perform new tasks with minimal examples.
The training of Large Language Models (LLMs) typically requires substantial computational resources and data. However, recent advancements like Parameter-Efficient Fine-Tuning (PEFT) and Low-Rank Adaptation (LoRA) offer more resource-efficient pathways to customize these models for specific tasks. This article explores how these methods enable efficient training and adaptation of LLMs.
Parameter-Efficient Fine-Tuning (PEFT):
PEFT is a collection of techniques designed to update a small subset of a pre-trained model’s parameters during the fine-tuning process. This approach is particularly useful when adapting LLMs to new tasks without the need to retrain the entire model, thus saving computational resources. Techniques under the PEFT umbrella include:
- Adapter Modules: Small neural network layers inserted between the layers of a pre-trained model. Only these adapters are trained, while the original model parameters remain frozen.
- Prompt Tuning: Instead of changing the model’s weights, prompt tuning adds a series of trainable vectors (prompts) to the model’s input, effectively guiding the model to produce the desired output.
- BitFit: A simple yet effective method where only the bias terms of the model are fine-tuned, leaving the rest of the parameters untouched.
Low-Rank Adaptation (LoRA):
LoRA is a training technique that modifies a pre-trained model by introducing low-rank matrices that capture important adaptations for specific tasks. The key steps in LoRA include:
- Identifying Weight Matrices: Selecting specific weight matrices within the model that are crucial for the task at hand.
- Low-Rank Decomposition: Decomposing these weight matrices into low-rank matrices that are smaller and thus require fewer parameters to be trained.
- Training: Updating only the low-rank matrices while keeping the original pre-trained weights fixed.
Training Process:
To train an LLM using PEFT or LoRA, one would typically follow these steps:
- Pre-Training: Start with a model that has been pre-trained on a large, general dataset.
- Selection: Choose the appropriate PEFT or LoRA technique based on the task, data availability, and resource constraints.
- Adaptation: Apply the chosen technique to adapt the model. For PEFT, this might involve inserting adapter modules or prompts. For LoRA, this involves identifying and decomposing weight matrices.
- Fine-Tuning: Train the model on the task-specific dataset, adjusting only the parameters identified in the adaptation step.
- Evaluation: Assess the model’s performance on the task, and adjust the training process as needed to optimize results.