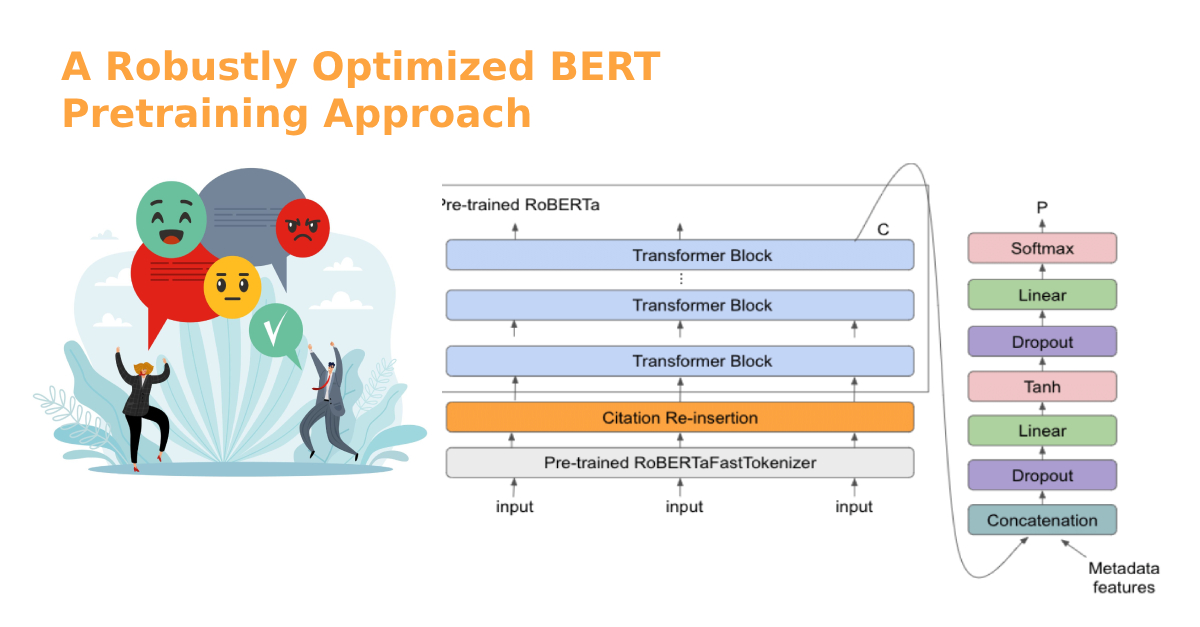
ROBERTa stands for “A Robustly Optimized BERT Pretraining Approach.” This is a model created by Facebook’s AI team, and it’s essentially an optimization of BERT (Bidirectional Encoder Representations from Transformers), one of the most influential natural language processing models. Both models belong to the Transformer architecture family, which has dramatically impacted the world of deep learning due to its incredible performance in capturing contextual relationships in texts.
Key Differences Between BERT and ROBERTa:
- Training Data and Size: ROBERTa was trained on more data than BERT. Specifically, ROBERTa was trained on a dataset that combines the English parts of five different corpora.
- Optimization: ROBERTa doesn’t use the next sentence prediction task that BERT uses during training. Instead, it relies solely on the masked language model (MLM) task, but with more data and larger batch sizes.
- Dynamic Masking: Unlike BERT, which has static masking, ROBERTa employs dynamic masking. This means that during pretraining, it changes the words that get masked each time a particular sentence is fed to the model.
Now, let’s delve into the workings of ROBERTa with Python examples.
ROBERTa in Action with Python
To work with ROBERTa, we’ll use the transformers library. If you haven’t installed it yet, you can do so with pip:
pip install transformers1. Text Classification with ROBERTa:
For this task, we’ll use ROBERTa’s base model, roberta-base.
from transformers import RobertaTokenizer, RobertaForSequenceClassification
import torch
# Loading the model and tokenizer
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
model = RobertaForSequenceClassification.from_pretrained('roberta-base')
# Sample text
text = "ROBERTa is a variant of BERT."
# Encoding text and getting classification logits
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
# The logits are the model's predictions
logits = outputs.logits
print(logits)
2. Masked Language Model with ROBERTa:
Here’s an example where we use ROBERTa to predict masked words:
from transformers import RobertaTokenizer, RobertaForMaskedLM
# Loading the model and tokenizer
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
model = RobertaForMaskedLM.from_pretrained('roberta-base')
# Masking a token in a sentence
text = "ROBERTa is a variant of [MASK]."
inputs = tokenizer(text, return_tensors="pt")
# Getting the predictions
outputs = model(**inputs)
predictions = outputs.logits
# Finding the predicted token
predicted_index = torch.argmax(predictions[0, -1, :]).item()
predicted_token = tokenizer.convert_ids_to_tokens([predicted_index])[0]
print(predicted_token) # This should print "BERT"
3. Fine-Tuning ROBERTa on Custom Data:
For this example, let’s assume we have a binary classification problem.
from transformers import RobertaTokenizer, RobertaForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# Sample dataset
dataset = load_dataset('glue', 'mrpc')
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
# Tokenize our dataset
def tokenize_function(examples):
return tokenizer(examples['sentence1'], examples['sentence2'], padding='max_length', truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Define the model
model = RobertaForSequenceClassification.from_pretrained('roberta-base', num_labels=2)
# Define training arguments and train
training_args = TrainingArguments(per_device_train_batch_size=8, logging_dir='./logs', output_dir='./results', num_train_epochs=3, evaluation_strategy="steps", eval_steps=500, logging_steps=250)
trainer = Trainer(model=model, args=training_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["validation"])
trainer.train()
Please note that this is a simplified example for demonstration purposes. In real-world applications, fine-tuning a model involves more in-depth considerations such as learning rate schedules, handling class imbalance, and more.
ROBERTa for Product Review Sentiment Analysis
- Collect and Prepare the Data:Begin by collecting product reviews. Typically, these reviews come with ratings. For simplicity, assume:
- Reviews with 4-5 stars are positive (labelled as 1).
- Reviews with 1-2 stars are negative (labelled as 0).
- Reviews with 3 stars can be ignored or treated as neutral.
Fine-Tuning ROBERTa:
Using the transformers library and the dataset structure explained before:
from transformers import RobertaTokenizer, RobertaForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
# Assume 'reviews' is a custom dataset with the fields 'text' and 'label'
# You can convert your data to the required format and use `load_dataset` to load it
dataset = load_dataset('path_to_your_dataset')
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
# Tokenize our dataset
def tokenize_function(examples):
return tokenizer(examples['text'], padding='max_length', truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Define the model
model = RobertaForSequenceClassification.from_pretrained('roberta-base', num_labels=2)
# Training arguments
training_args = TrainingArguments(per_device_train_batch_size=8, logging_dir='./logs', output_dir='./results', num_train_epochs=3, evaluation_strategy="steps", eval_steps=500, logging_steps=250)
# Train the model
trainer = Trainer(model=model, args=training_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["validation"])
trainer.train
Inferencing and Analysis:
Once you’ve fine-tuned ROBERTa, you can use it to predict sentiments of new reviews.
def classify_sentiment(text):
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
prediction = torch.argmax(logits, dim=1).item()
return "Positive" if prediction == 1 else "Negative"
review = "This product is fantastic!"
print(classify_sentiment(review)) # Expected: Positive
Insights and Actions:
- Trending Products: By analyzing which products get the most positive reviews, you can identify your best-sellers or high-quality products.
- Areas of Improvement: Negative reviews can highlight areas where your products or services can be improved.
- Customer Engagement: You can reach out to customers who leave negative reviews to understand their concerns better and improve your relationship with them.
Conclusion
ROBERTa has taken the foundational architecture of BERT and improved upon it by optimizing its training process. Due to its effectiveness, it’s being adopted in various NLP applications, from text classification to machine translation. With the transformers library in Python, leveraging the power of ROBERTa has never been easier. Using ROBERTa for sentiment analysis in product reviews provides business owners with valuable insights. By understanding customer sentiment, businesses can make informed decisions to enhance their products, address concerns, and ultimately improve their relationship with their customers.